!
ПАК «Капля»
Разговор об отечественном ПАК «Капля» с замдиректора НИИ «Энергомашиностроения» МГТУ им. Баумана Максимом Французовым
Это интервью родилось из очередного пресс-релиза от российских разработчиков, выложенного на сайте МГТУ им. Баумана. Пресс-релиз представлял собой короткий рассказ, что был создан программно-аппаратный комплекс (ПАК) с двухфазным охлаждением. Сначала хотели написать новость, запросив технические детали у МГТУ. Однако потом, во время общения с представителями МГТУ, пришла идея сделать материал побольше. Поэтому я отправился в МГТУ им. Баумана общаться с заместителем директора НИИ Энергетического Машиностроения МГТУ им. Баумана Французовым Максимом Сергеевичем. И вот что из этого получилось.

Этот проект — совместный проект МГТУ с НИИ «Энергомашиностроения»?
НИИ «Энергомашиностроения» входит в МГТУ им. Баумана. Поэтому проект, по сути, самого университета.
Ваша платформа производится на мощностях вашего университета, или же вы всё‑таки сотрудничаете с каким‑то вендором?
Безусловно, в части отечественного программно‑аппаратного комплекса мы взаимодействуем с МЦСТ и НТЦ «Модуль». Они являются производителями тех составных частей, которые мы используем, ставим в свой программно‑аппаратный комплекс. МЦСТ создаёт процессоры «Эльбрус» и серверную плату, а НТЦ «Модуль» создаёт ускорители, которые фактически являются некоторым аналогом иностранных графических ускорителей.
Получается, корпус каждый раз вы заказываете в разных местах, или есть производитель, поставляющий вам корпуса? Серверные стойки вы тоже у кого‑то заказываете или всё производится на мощностях университета?
Что касается сварки или гибки большого листового металла, это мы всё, безусловно, заказываем у внешних производителей. Но есть вещи, которые мы делаем здесь, в стенах университета: это теплообменники, поверхности для кипения, для конденсации — скажем так, мы стараемся производить всё то, что можно сделать быстро или рентабельно в стенах университета. В остальном стараемся обращаться к профессионалам, где это возможно.
Скажите, если вдруг будет получаться типовое решение, вы его будете стараться производить внутри университета, кроме комплектующих? Или собирать типовое решение будет какой‑то завод, с кем вы сможете договориться? Или уже есть какие‑то договорённости?
Здесь всё зависит от масштаба производства. Поскольку, если это будут десятки штук в год или в полгода, то, конечно, мы всё сделаем внутри университета, нам для этого сил хватит. Единственно, что есть особенности по работе с бюджетом — это 44 ФЗ и 223 ФЗ. Но для этого у нас есть фирмы, которые являются таким коммерческим ответвлением от университета. Эти фирмы позволяют некоторые вопросы, необходимые в коммерции для быстрой закупки, решать вне бюджетного контура.
Каких‑то договорённостей у нас нет, разве что с теми производителями компьютерного железа, с которым мы взаимодействуем. Это не только касается графических ускорителей и центральных процессоров. Это касается, например, SSD накопителей, которые мы тоже стараемся, чтобы были отечественными, потому что есть история, когда это по сути Transcend, но сверху наклеили название какой‑нибудь российской компании. Вот поэтому мы стараемся самым плотным образом взаимодействовать с полностью российскими производителями компьютерного железа, и по части всей периферии, и даже с точки зрения интерконнекта. В плане интерконнекта у нас есть интересные повязки с АО «НИИЦЕВТ».
Какие в вашем решении задействованы комплектующие, если не по моделям, то хотя бы по сериям. Какой был прототип изначально в 2018 году, и как всё поменялось спустя 5 лет?
Ну, изначально прототипом был сервер Gigabyte, но под процессор Intel. Там использовалось 2 процессора Intel Xeon Gold 6242R и 6 штук Nvidia Tesla V100. Мы специально хотели создать максимально высокоплотное решение, если пересчитывать в терафлопсы, то это там порядка 50 терафлопс на сервер 2U, что для большинства практических приложений хорошо подходит. Здесь важным показателем, которым мы фиксировали энергоэффективность, был PUE. В прототипе он получился на уровне 1,02— 1,04. Мы особо не старались его как‑то оптимизировать. Это получилось само собой из‑за особенностей системы охлаждения. А после того, как мы смогли, скажем так, найти в публичном поле то, что было из зарубежных комплектующих, и обойти по производительности и по энергоэффективности аналоги, мы переключились на отечественную ЭКБ.


И вот, в 2022 году создали решение, и оно на сегодняшний день продолжает работать — это четырёхпроцессорная серверная плата «Эльбрус» 4Э8СВ‑MSWTX, 4 процессора «Эльбрус-8СВ», 4 NM‑card‑модуля. Для NM‑card‑модулей мы используем райзеры специальной гибкой конструкции отечественной фирмы «Промоудс». Такая разработка позволяет в толщине буквально меньше 1U расположить высокую плотность. Если считать вместе с картами, то, по‑моему, там порядка 3 или 3,5 терафлопс вычислительной мощности. Также у нас тоже есть поставщик твердотельных накопителей для этой системы. Единственное, что осталось иностранным — это оперативная память SAMSUNG DDR4 64 GB RDMIMM 2933.

Получается, что, по большом счёту, это решение процентов на 95 российское?
Да.
Понятно, а не думали переходить на китайскую память? Не тестировали ещё?
Мы много работали с китайскими элементными базами. В частности, у нас была одна работа с Huawei, где мы применяли тот же принцип для них и тоже добились результатов.
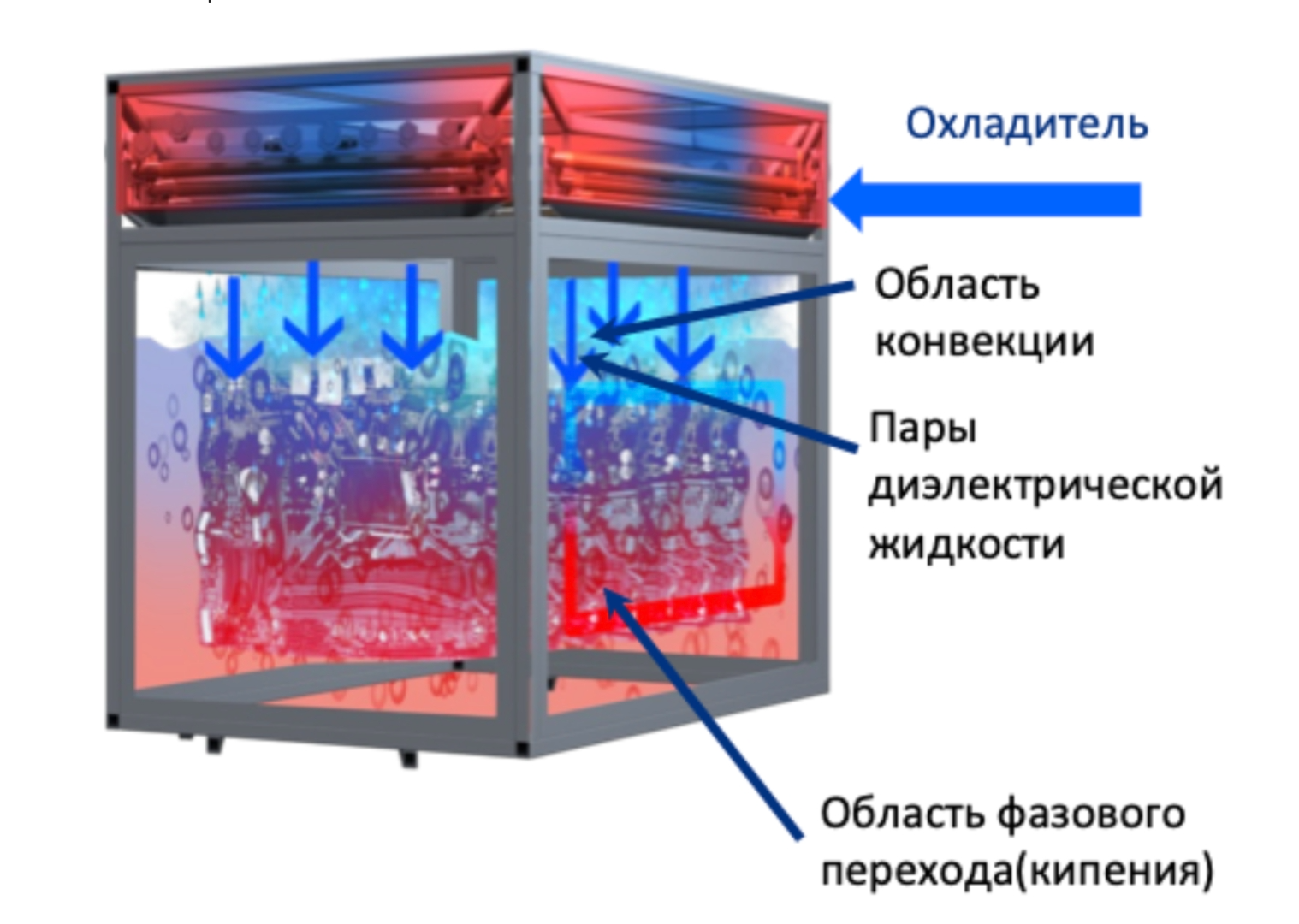
Что представляет собой ваша система охлаждения: как реализовано и как это будет выглядеть в типовом решении? В вашем пресс‑релизе указано, что это ваше ноу‑хау.
24 марта 2023 года случилось неприятное событие: умер Гордон Мур, правда, было ему 94 года. Гордон Мур является автором знаменитого закона Мура, в котором говорится об удвоении транзисторов на чипе. Так вот, следуя этой тенденции, плотность тепловыделения на процессорах так стремительно растёт, что ещё 5 лет назад превысила плотность тепловыделения в ядерном реакторе. И нам известно, что все компании, та же Microsoft или та же Gigabyte из другой части света, активно занимаются поиском новых способов отвода тепла от высокопроизводительной высоконагруженной электроники.
Вот и, в частности, когда мы сами столкнулись с этой задачей, мы должны были применить какой‑то новый физический принцип, который находится в стороне от привычных контактных водяных систем охлаждения и от воздушных систем охлаждения, которые являются чрезвычайно прожорливыми энергетическими машинами.
Мы используем способы двухфазного охлаждения. В этом случае тепловыделяющие электронные компоненты напрямую помещаются на диэлектрическую жидкость. Диэлектрические свойства этой жидкости лучше, чем у воздуха, реализуется теплота фазового перехода, который на 2 порядка превосходит все любые способы отвода тепла по коэффициенту теплоотдачи.
И вот, реализовав такой принцип, можно иметь существенно более компактное высокопроизводительное решение, чем есть, ну так будем говорить так, в традиционном бытовом использовании. Жидкость, которую мы используем, кипит при температуре 61о. Я тут должен отметить, что в мире используют иностранную жидкость компании 3М, у нас жидкость отечественная.
Мы вместе с Институтом Российской академии наук по неорганической химии разработали рецептуру жидкости, кипящую при температуре 61о, конденсирующуюся при температуре 57о, замерзающую при температуре ниже –130о, что делает возможность создания в будущем центров обработки данных практически во всепогодных условиях.
Эта система охлаждения позволяет добиться высокой энергоэффективности. У нас всего 2% без оптимизации уходит на обеспечение всей инженерной периферии: драйкулеры, насосы и прочее, прочее.
Поэтому эта система охлаждения может позволить создавать компактные сервера и, соответственно, энергоэффективные центры обработки данных.
Кстати, можно посмотреть по ЦОДам, например, у фирмы Alibaba строится ЦОД размером 119 футбольных полей. По законодательным нормам Китая нельзя выбрасывать сильно горячий воздух в атмосферу, и PUE у этого ЦОДа в районе 2.
Создавая такие системы, мы могли бы приблизиться к другой энергоэффективности. Сейчас уже можно не бояться переходить к другой логике построения центров обработки данных, суперкомпьютерных центров и так далее. Мы сейчас находимся в одном из пилотных проектов.
Как ваша разработка появилась, как вы пришли к этому решению, сначала с Gigabyte, а потом c российскими комплектующими?
В 2018 году к нам обратилась одна из фирм‑интеграторов. От фирмы стояла задача по отведению тепла производительной электроники, который бы превосходил такой удельный показатель, как плотность тепловыделения на м3. Необходимо было отвести более 150 кВт с м3. Традиционно для таких подходов использовались масляные системы охлаждения. Это достаточно грязно и не очень технологично. Появляется дополнительный технологический процесс: прежде чем обслуживать сервера, нужно их отмыть от загрязнения.
Мы должны были подойти к решению этой задачи по‑новому. Поэтому мы пришли к необходимости использовать двухфазный подход. Поскольку в МГТУ им. Баумана есть школа двухфазного теплообмена, десятилетиями стоящая на научной основе и на инженерных подходах, это нам позволило создать систему охлаждения, способную отводить с м3 более 300 кВт тепла. Посмотрев все дорожные карты по созданию новых техпроцессов, новых чипов, новых процессоров, мы увидели, что на ближайшую перспективу такого подхода хватает, и, соответственно, решили переходить уже к действующему образцу.
Таким действующим образцом стал сервер компании Gigabyte, в котором мы охлаждали 6 видеокарт Nvidia Tesla и 2 процессора Intel Xeon Gold. Даже у Gigabyte, возившего по мировым выставкам похожую разработку, была плотность тепловыделения на порядок меньше примерно с того же объёма. У нас и до сих пор на прототипе с Gigabyte решаются настоящие задачи по нейросетям и по суперкомпьютерному моделированию.
Насколько сложно было переходить с решения Gigabyte на решение российских вендоров?
Ну, главным образом это, конечно, форм-фактор. Он, в общем-то, до некоторой степени нестандартный, но наши заказчики это понимали и поэтому пошли здесь нам навстречу. Будем так говорить: вся стандартная периферия, которая есть, находится в логике 1U, 2U и так далее. И поэтому нам здесь было несколько сложно. Но если взять решения с «Эльбрусом», NM-card устанавливается в PCI Express-разъём. Поэтому мы используем гибкий райзер и получается тонкий блейд-сервер, определяемый, фактически, высотой оперативной памяти, используемой нами. Но в целом и то, и другое решение, что Gigabyte, что МЦСТ «Эльбрус», это всё-таки воздушная логика построения вычислительных плат. Поэтому для таких высокопроизводительных систем надо переходить к платам, использующим другую логику построения для охлаждения. Могу сказать, что сейчас мы делаем проект для одного банка. В этом проекте 96 ядер процессора AMD, 2U сервер, в котором расположены 4 ноды, и в каждой ноде по 2 процессора. Это более высокопроизводительная вычислительная сборка, чем тестовая, о которой я говорил. Но у банка стоит очень чёткая задача максимизировать число ядер центрального процессора на м2.
У вас в пресс-релизе программно-аппаратный комплекс называют ЦОДом, мини-ЦОДом. Я правильно понимаю — этот ЦОД имеет систему автономной работы на случай потери электропитания, может обеспечивать несколько рабочих мест, у него предусмотрена возможность резервирования данных. В целом, в нём реализована отказоустойчивость?
Вычислительный узел в белом корпусе это фактически один узел микро-ЦОДа. В этот микро-ЦОД помещается с одной стороны 24 таких вычислительных узла и, соответственно, с двух сторон это 48 вычислительных узлов на высоту стандартной серверной стойки (42U). При этом инженерная инфраструктура остаётся высотой полстойки.

У нас задублированные в системе насосы, зарезервировано питание по N+1. Хотя это не проектировалось, скажем так, для сугубо гражданского назначения, тем не менее мы рассматривали проект, который бы мог бы нас приблизить к Tier 3. Но здесь мы подвязаны на заказчика.
Если говорить о некоторой автономии, то место, где микро-ЦОД должен быть установлен — это военно-инновационный технополис «Эра». Там всё зависит от их дизеля и хранилища. Однако потенциально в проекте это для отказоустойчивовсти всё, конечно, есть. Увязку со всей инженерной инфраструктурой мы сделали. Пока мы, естественно, на площадке заказчика не развернулись. Когда развернёмся, я думаю, сможем всё показать и продемонстрировать.
Что касается отказоустойчивости, если в системе вытащить какой-то узел и начать обслуживать, остальные узлы будут продолжать работать в штатном режиме. В микро-ЦОДе есть система хранения данных, зарезервировано питание, зарезервированы насосы и тепловентиляторы. По проекту всё зарезервировано по классу, близкому к Tier 3.
Вопрос такой: если мы рассматриваем идеальные условия, возможно на базе этого решения создать контейнерный ЦОД?
Если говорить про логику исполнения мобильного, то к примеру, на стандартный сорокафутовый контейнер компания Huawei предлагает порядка 200-250 кВт мощности. Используя наше решение, в контейнерном ЦОДе можно разместить до 1 МВт мощности без всякой нагрузки, на так называемых «воздушных» серверах. И это без ухищрений по железной части. Если применить ухищрения, то соответственно, можно говорить о мощностях внутри одного контейнера больше 1 МВт.
Да и жидкость — это совершенно другая пожаробезопасность, поэтому мы не завязаны на систему пожаротушения. В ЦОДе по правилам мы должны её соблюдать. Однако у нас полная пожаробезопасность, воспламенение если возможно, то в другой, открытой электрической части.
Программное обеспечение в вашем ПАКе представляет собой переработанное open source решение или разработанное с нуля? Оно типовое или разрабатывается под конкретного заказчика?
Я скажу только по той части, которая сделана и работает в МГТУ им. Баумана. Это специализированный программный комплекс «Гиперкуб» и наш, написанный с нуля, код «Манипула». Что касается массового сегмента прикладного инженерного ПО — это пакет программ «Логос», прикладное инженерное ПО FlowVision, «ОС Эльбрус». Также вместе с НТЦ «Модуль» нам удалось разработать тест производительности. Тест фиксирует максимум производительности на NM Card.
Ваше решение разрабатывается под бизнес или под госведомства, или вам неважно, под кого его разрабатывать? Вы собираете конкретное решение под конкретного заказчика и от этого зависит, нужно ли его сертифицировать во ФСТЭК, ФСБ? То есть типовых решений пока нет?
Да, действительно типовых решений нет. И вот мы сегодня уже с вами упоминали и ту, и другую группу заказчика. В принципе, заказчик от бизнеса просит гарантии, которые главным образом распространяются на железо, поскольку именно компьютерное железо составляет большую часть стоимости решения. И когда заказчик хочет, чтобы оно там 3 года в такой среде работало с такой системой охлаждения или даже 5 лет, мы вынуждены взаимодействовать с теми вендорами, с теми производителями, которые такую гарантию в состоянии дать. На момент 2021 года у нас была прямая гарантия от компании Gigabyte на сервер в сборе, то есть включая процессоры Intel, карты Nvidia. Gigabyte давали гарантию на 3 года за относительно небольшую стоимость от суммарной цены. И если говорить про коммерческого заказчика, они смотрят в сторону того, кто готов дать такую гарантию. Им важно, чтобы там на протяжении 3 лет было хоть какое-то подтверждение того, что это отработает согласно проектным характеристикам.
Ваш ЦОД лёгок в установке и обслуживании? Как реализуется установка? Первый вариант: вы даете решение, фирма у себя его ставит, запускает. Если с ним какие‑то проблемы, они просят, чтобы приехал ваш технический специалист?
Второй вариант: установку выполняете вы, а потом заказчик решение эксплуатирует. В какой‑то момент возникают вопросы по решению, и заказчик обращается к вам?
И третий вариант: зависит от контракта, который заказчик заключил с вами. Например, у вас есть несколько уровней поддержки: базовая, обычная, премиум и VIP?
У нас нет пока такого реализованного кейса, где бы мы могли похвастаться, что вот наше решение уже там на протяжении 3 лет где‑то эксплуатируется. Поскольку мы находимся в стенах университета, то ребята, на сегодняшний день работающие с системой, запускающие, выключающие, обслуживающие и так далее её, — вчерашние студенты, которые достаточно быстро освоили логику смены обслуживания с воздушных серверов на сервера погружного типа.
Конечно, с точки зрения обслуживания этот подход отличается от традиционных воздушных серверов, тем не менее, он в общем‑то доступен специалисту обычной квалификации, который когда‑то подходил к серверному оборудованию.
В частности, с банковским проектом мы договорились, что обучим их специалистов, чтобы не было больших критических ошибок при обслуживании системы. Но в целом, я думаю, что IT‑специалисты банка в принципе довольно быстро подхватят эту технологию и смогут работать, в том числе и с погружными серверами.
Если подводить итог — компетенций обычного системного администратора, специалиста технической поддержки IT вполне хватит для системы погружного охлаждения.
Заключение
Под конец интервью была продемонстрирована жидкость, использующаяся в двухфазной системе охлаждения сервера. Максим Сергеевич взял бумажку и побрызгал охлаждающей жидкостью — она довольно быстро испарилась с бумажки, не оставив никаких пятен и разводов.
© НУК «Энергомашиностроение»
МГТУ им. Н. Э. Баумана, 2015—2025
8 499 263-65-16
Москва, Лефортовская наб., д. 1
Разработано в Научно-образовательном центре
«Электронный университет»
|
google+
|
vk
|
facebook
|
Tweet |